
What’s that big cloud over the rainforest?
As the .com shakeout loomed in the late 90s, I always assumed that:
- Most internet-born companies would disappear.
- Traditional (brick & mortar) stores would eventually get their act together and have (or outsource) a proper online presence. For instance Barnes & Noble hobbling toward a usable site, and Borders just giving up and turning over their online presence to Amazon. The former comical, the latter brilliant, though Borders has just returned with their own non-Amazonian presence. (Though I think the humor is now gone from watching old-school companies trying to move online.)
- Finally, a few new names—namely the biggest ones, like Amazon—would be left that didn’t disappear with the others from point #1.
Basically, that not much would change. A couple new brands would emerge, but that there wasn’t really room in people’s heads for that many new retailers or services. (It probably didn’t help that all their logos were blue and orange, and had names like Flooz, Boo and Kibu that feel natural on the tongue and inspire buyer loyalty and confidence.)
 But not only did more companies stick around, some seem to be successfully pivoting into other areas. From Amazon:
But not only did more companies stick around, some seem to be successfully pivoting into other areas. From Amazon:
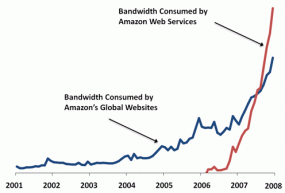
In January of 2008 we announced that the Amazon Web Services now consume more bandwidth than do the entire global network of Amazon.com retail sites.
This from a blog post with this plot of the bandwidth use for both sides of the business.
Did you imagine that the site where you could buy books cheaper than anywhere else in 1998 would ten years later exceed the bandwidth from that with services for data storage and cloud computing? Of course, this announcement doesn’t say anything about their profits at this point, but I don’t think anyone expected Steve Jobs to turn Apple into a toy factory and start turning out music players and cell phones to have it become half their business within just a few years. (That’s half as in, “beastly silver PCs and shiny black and white laptops seem important and all, but those take real work…why bother?”)
But the point (aside from subjecting you to a long-winded description of .com history and my shortcomings as a futurist) has more to do with Amazon becoming a business that’s dealing purely in information. The information economy is all about people moving bits and ideas around (abstractions of things), instead of silk, furs, and spices (actual physical things). And while books are information, the growth of Amazon’s data services business—as evidenced by that graph—is one of the strongest indicators I’ve seen of just how real the non-real information economy has become. Not that the information economy is something new; but that the groundwork has been laid in the preceding decades where something like Amazon Web Services can be successful.
And since we’re on the subject of Amazon, I’ll close with more from Jeff Bezos from “How the Web Was Won” in this month’s Vanity Fair:
When we launched, we launched with over a million titles. There were countless snags. One of my friends figured out that you could order a negative quantity of books. And we would credit your credit card and then, I guess, wait for you to deliver the books to us. We fixed that one very quickly.
Or showing his genius early on:
When we started out, we were packing on our hands and knees on these cement floors. One of the software engineers that I was packing next to was saying, You know, this is really killing my knees and my back. And I said to this person, I just had a great idea. We should get kneepads. And he looked at me like I was from Mars. And he said, Jeff, we should get packing tables.
Thanks to Eugene for passing along the links.
