
Glancing at Tax Proposals
Finally, the infographic I’ve been waiting for, the Washington Post compares the tax proposals of United States presidential candidates John McCain and Barack Obama:
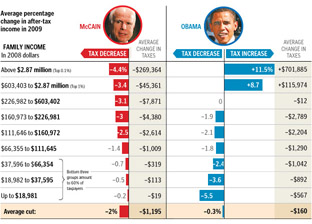
Lots of words have been spilled over the complexities of tax policy, whether in stump speeches, advertisements, or policy papers. But these are usually distilled for voters in lengthy articles that throw more words at the problem. But compare even a well-written article like this one at Business Week versus the graphic above from the Washington Post. Which of the two will you be able to remember tomorrow?
I also appreciate that the graphic very clearly represents the general tax policies of Republicans vs. Democrats, without showing bias toward either. The only thing that’s missing is a sense of how big each of the categories are – how many people are in the “over $2.87 million” category versus how many are in the “$66,000 to $112,000” category, which would help convey a better sense of the “middle class” term that candidates like to throw around.
There is still greater complexity to the debate than what’s shown in this image (the Business Week article describes treasury shortfalls based on the McCain proposal, for instance), but without the initial explanation provided by that graphic, will voters even bother with those details?
