A simple, interactive means for seeing connections between demographics, diseases, and diagnoses:
We just finished developing this project for GE as part of the launch of their new health care initiative. With the input and guidance of a handful of departments within the company, we began by looking at their proprietary database of 14 million patient records looking for ways to show connections between related conditions. For instance, we wanted visitors to the site to be able to learn how diabetes diagnoses increase along with obesity, but convey it in a manner that didn’t feel like a math lesson. By cycling through the eight items at the top (and the row beneath it), you can make several dozen comparisons, highlighting what’s found in actual patient data. At the bottom, some additional background is provided based on various national health care studies.
I’m excited to have the project finished and online, and have people making use of it, as I readjust from the instant gratification of building things one day and then talking about them the next day. More to come!
Depicting networks (also known as graphs, and covered in chapters 7 and 8 of Visualizing Data) is a tricky subject, and too often leads to representations that are a tangled and complicated mess. Such diagrams are often referred to with terms like ball of yarn or string, a birds nest, cat hair or simply hairball.
It’s also common for a network diagram to be engaging and attractive for its complexity (usually aided and abetted by color), which tends to hide how poorly it conveys the meaning of the data it represents.
On the other hand, Tamara Munzner is someone in visualization who really “gets” graphs in greater depth. A couple years ago she gave an excellent Google Tech Talk (looks like it was originally from another conference in ’05), titled “15 Views of a Node Link Graph” (video, links, slides) where she discussed a range of methods for working viewing graph data, along with their pros and cons:
A cheat sheet of the 15 methods:
Edge List
Hand-Drawn
Dot
Force-Directed Placement
TopoLayout
Animated Radial Layouts
Constellation
Treemaps
Cushion Treemaps
Themescapes
Multilevel Call Matrices
SpaceTree
2D Hyperbolic Trees
H3
TreeJuxtaposer
The presentation is an excellent survey of methods, and highly recommended for anyone getting started with graph and network data. It’s useful food for thought for the “how should I represent this data?” question.
I was in the midst of starting a new post in January so I failed to make a post about it at the time, but Oblong‘s Tamper installation was on display at the 2009 Sundance Film Festival. John writes (and I copy verbatim):
Our Sundance guests — who already number in the thousands — find the experience exhilarating. A few grim cinephiles have supplementally raised an eyebrow (one per cinephile) at the filmic heresy that TAMPER provides: a fluid new ability to isolate, manipulate, and juxtapose (rudely, say the grim) disparate elements (ripped from some of the greatest works of cinema, continue the grim). For us, what’s important is the style of work: real-time manipulation of media elements at a finer granularity than has previously been customary or, for the most part, possible; and a distinctly visceral, dynamic, and geometric mode of interaction that’s hugely intuitive because the incorporeal suddenly now reacts just like bits of the corporeal world always have. Also, it’s glasses-foggingly fun.
I mostly find this fascinating having not seen it properly depicted, but the interactive version shows more about locations of power plants, plus maps of solar and wind power along with their relative capacities.
I love the craggy beauty of the layered lines, and appreciate the restraint of the map’s creators to simply show us this amazing data set.
And if you find yourself toe tapping and humming “we gonna rock down to…” later this afternoon, then I’m really sorry. I’m already beginning to regret it.
I’ve not been working on Windows much lately, but while installing Windows XP today, I was greeted with this fine work of nonfiction, which reminds me why I miss it so:
So I can’t synchronize the time because…the time on the machine is incorrect. And not only that, but my state represents a security risk to the time synchronization machine in the sky.
I hope the person who wrote this error message enjoyed it as much as I did. At least when writing bad error messages in Processing I have some leeway for making fun of the situation (hence the unprofessional window titles of some of the error dialogs).
Reader Eric Mika sent a link to the video of Obama’s speech that I mentioned a couple days ago. The speech was knocked from the headlines by news of Arlen Specter leaving the Republican party within just a few hours, so this is my chance to repeat the story again.
Specter’s defection is only relevant (if it’s relevant at all) until the next election cycle, so it’s frustrating to see something that could affect us for five to fifty years pre-empted by what talking heads are more comfortable bloviating about. It’s a reminder that with all the progress we’ve made on how quickly we can distribute news, and the increase in the number of outlets by which it’s available, the quality and thoughtfulness of the product has only been further undermined.
Update, a few hours later: it’s a battle of the readers! now Jamie Alessio passed along a high quality video of the the President’s speech from the White House channel on YouTube. Here’s the embedded version:
Author Ben Fry will be presenting “Computational Information Design” –a mix of his work in visualization and coding plus a quick introduction to Processing. We are very excited to talk to Mr. Fry and our thanks go out to this event’s sponsors: Atalasoft and Snowtide Informatics.
I believe it is not in our American character to follow – but to lead. And it is time for us to lead once again. I am here today to set this goal: we will devote more than three percent of our GDP to research and development. We will not just meet, but we will exceed the level achieved at the height of the Space Race, through policies that invest in basic and applied research, create new incentives for private innovation, promote breakthroughs in energy and medicine, and improve education in math and science. This represents the largest commitment to scientific research and innovation in American history.
I’m not much for patriotism rah-rah but it’s hard not to get fired up about this. I found the rest of his speech remarkable as well, listing specific technologies that emerged from basic research, too often overlooked:
The Apollo program itself produced technologies that have improved kidney dialysis and water purification systems; sensors to test for hazardous gasses; energy-saving building materials; and fire-resistant fabrics used by firefighters and soldiers.
And the announcement of a new agency along the lines of DARPA:
And today, I am also announcing that for the first time, we are funding an initiative – recommended by this organization – called the Advanced Research Projects Agency for Energy, or ARPA-E.
This is based on the Defense Advanced Research Projects Agency, known as DARPA, which was created during the Eisenhower administration in response to Sputnik. It has been charged throughout its history with conducting high-risk, high-reward research. The precursor to the internet, known as ARPANET, stealth technology, and the Global Positioning System all owe a debt to the work of DARPA.
The speech, nearly 5000 words in total (did our former President spill that many words for science during eight years in office?) continues with more policy regarding research, investment, and education–all very exciting to read. But perhaps my most favorite line of all, when he said to the members of the National Academy of Sciences in attendance:
And so today I want to challenge you to use your love and knowledge of science to spark the same sense of wonder and excitement in a new generation.
Word on the street (where by “the street” I mean an email from Golan Levin), is that the Center for Responsive Politics has made available piles and piles of data:
The following data sets, along with a user guide, resource tables and other documentation, are now available in CSV format (comma-separated values, for easy importing) through OpenSecrets.org’s Action Center at http://www.opensecrets.org/action/data.php:
CAMPAIGN FINANCE: 195 million records dating to the 1989-1990 election cycle, tracking campaign fundraising and spending by candidates for federal office, as well as political parties and political action committees. CRP’s researchers add value to Federal Election Commission data by cleaning up and categorizing contribution records. This allows for easier totaling by industry and company or organization, to measure special-interest influence.
LOBBYING: 3.5 million records on federal lobbyists, their clients, their fees and the issues they reported working on, dating to 1998. Industry codes have been applied to this data, as well.
PERSONAL FINANCES: Reports from members of Congress and the executive branch that detail their personal assets, liabilities and transactions in 2004 through 2007. The reports covering 2008 will become available to the public in June, and the data will be available for download once CRP has keyed those reports.
527 ORGANIZATIONS: Electronically filed financial records beginning in the 2004 election cycle for the shadowy issue-advocacy groups known as 527s, which can raise unlimited sums of money from corporations, labor unions and individuals.
The best thing here is that they’ve already tidied and scrubbed the data for you, just like Mom used to. The personal finance information alone has already led to startling revelations.
A code jam / party and programming competition
Part of the Boston Cyberarts Festival
Saturday, May 2, 2009 – MIT N52–390
265 Massachusetts Ave, 3rd Floor Concept
Compete individually or in pairs to design and develop beautiful programs in Processing
Snack and refresh yourself
Present completed projects to other participants and visitors at the end of the day
Anyone (not just MIT students or community members) can compete, anyone can stop by to see presentations
Meet the creators of Processing, Ben Fry (in person) and Casey Reas (via video), who will award prizes
Schedule
12:30-01:00 pm: Check in
01:00-01:15 pm: Welcome
01:15-05:15 pm: Coding Session
05:15-06:45 pm: Presentations and Awards – Public welcome!
Registration
Register in advance, individually or in two-person teams, by emailing processing-time@mit.edu with one or two participant names and a team name.
Festival
Processing Time is sponsored by MIT (Arts Initiatives at MIT, Center for Advanced Visual Studies, Program in Writing & Humanistic Studies) and is part of the Boston Cyberarts Festival.
The Processing Time page, linked to a nifty poster, is at: burgess.mit.edu/pt
I’ve been working on ways to visualize the current world economic situation along with the bailouts, the Recovery and Reinvestment Act, and so on, but South Park beat me to it.
New work! Sometime collaborator and savior of this site Eugene Kuo and I have developed a piece for the PARSE show opening tomorrow (Friday, March 27) at the Axiom Art Gallery in Boston. From the announcement:
Curated by AXIOM Founding Director, Heidi Kayser, PARSE, includes the work of five artists who use data to present new perspectives on the underlying information that makes us human. Overlooked patterns of data surround us daily. The artists in PARSE sort, separate and amalgamate physical, mental and social information to create intricate visualizations in print, interactive media, animation and sculpture. These pieces track and reflect our brainwaves during REM sleep, our genetic code, our social icons, and even our carnal desires.
Featuring works by: Ben Fry and Eugene Kuo, Fernanda Viegas and Martin Wattenberg, Jason Salavon, Jen Hall
The opening is from 6-9pm. The gallery location is amazing — it’s a nook to the side of the Green Street subway station (on the Orange Line in Boston) — it makes me think of what it might be like to have a show at the lair of Bill Murray’s character in Caddyshack. I love that it’s been reserved as a gallery space.
Martin & Fernanda are showing their Fleshmap project, along with a pair of amalgamations by Jason Salavon, and two sculptures from Jen Hall (hrm, can’t find a link for those). Our project is described here, and uses comparisons of the DNA between many species that have been the focus of my curiosity recently to make compositions like the one seen to the right.
I happened across On the Marionette Theatre by Heinrich von Kleist while reading the Wikipedia entry on Philip Pullman’s His Dark Materials series. Pullman had cited it as one of three influences, and it being the shortest of the three, I gave it a shot (naturally, due to my apparent “young adult” reading level that found me reading his trilogy in the first place).
The story begins with the writer having a chance meeting with a friend, and inquiring about his apparent interest in puppet theater. As the story moves on:
“And what is the advantage your puppets would have over living dancers?”
“The advantage? First of all a negative one, my friend: it would never be guilty of affectation. For affectation is seen, as you know, when the soul, or moving force, appears at some point other than the centre of gravity of the movement. Because the operator controls with his wire or thread only this centre, the attached limbs are just what they should be.… lifeless, pure pendulums, governed only by the law of gravity. This is an excellent quality. You’ll look for it in vain in most of our dancers.”
The remainder is a wonderful parable of vanity and grace.
Welcome to the future, where everything about you is saved. A future where your actions are recorded, your movements are tracked, and your conversations are no longer ephemeral. A future brought to you not by some 1984-like dystopia, but by the natural tendencies of computers to produce data.
Data is the pollution of the information age. It’s a natural by-product of every computer-mediated interaction. It stays around forever, unless it’s disposed of. It is valuable when reused, but it must be done carefully. Otherwise, its after-effects are toxic.
The essay goes on to cite specific examples, though they sound more high-tech than the actual problem. Later it returns to the important part:
Cardinal Richelieu famously said: “If one would give me six lines written by the hand of the most honest man, I would find something in them to have him hanged.” When all your words and actions can be saved for later examination, different rules have to apply.
Society works precisely because conversation is ephemeral; because people forget, and because people don’t have to justify every word they utter.
Conversation is not the same thing as correspondence. Words uttered in haste over morning coffee, whether spoken in a coffee shop or thumbed on a BlackBerry, are not official correspondence.
And an earlier paragraph that highlights why I talk about privacy on this site:
And just as 100 years ago people ignored pollution in our rush to build the Industrial Age, today we’re ignoring data in our rush to build the Information Age.
Liskov, the first U.S. woman to earn a PhD in computer science, was recognized for helping make software more reliable, consistent and resistant to errors and hacking. She is only the second woman to receive the honor, which carries a $250,000 purse and is often described as the “Nobel Prize in computing.”
I’m embarrassed to admit that I wasn’t more familiar with her work prior to reading about it in Tuesday’s Globe, but wow:
Liskov’s early innovations in software design have been the basis of every important programming language since 1975, including Ada, C++, Java and C#.
Liskov’s most significant impact stems from her influential contributions to the use of data abstraction, a valuable method for organizing complex programs. She was a leader in demonstrating how data abstraction could be used to make software easier to construct, modify and maintain…
In another contribution, Liskov designed CLU, an object-oriented programming language incorporating clusters to provide coherent, systematic handling of abstract data types. She and her colleagues at MIT subsequently developed efficient CLU compiler implementations on several different machines, an important step in demonstrating the practicality of her ideas. Data abstraction is now a generally accepted fundamental method of software engineering that focuses on data rather than processes.
This has nothing to do with gender, of course, but I find it exciting apropos of this earlier post regarding women in computer science.
Update: As of January 1st, 2010, I’m no longer at Seed. Read more here.
Some eighteen months as visualization vagabond (roving writer, effusive explainer, help me out here…) came to a close in December when I signed up with Seed Media Group to direct a new visualization studio here in Cambridge. We now have a name—the Phyllotaxis Lab—and as of last week, we’ve made it official with a press release:
NEW YORK and CAMBRIDGE, MA (March 5, 2009) – Building on Seed Media Group’s strong design culture, Adam Bly, founder and CEO, announced today the appointment of Ben Fry as the company’s first Design Director. Seed Media Group also announced the launch of a new unit focused on data and information visualization to be based in Cambridge, Massachusetts and headed by Ben Fry.
Seed Visualization will help companies and governments find solutions to clearly communicate complex data sets and information to various stakeholders. The unit’s research arm, the Phyllotaxis Lab, will work to advance the field of data visualization and will undertake research and experimental design work. The Lab will partner with academic institutions around the world and will provide education on the field of data visualization.
And about that name:
Phyllotaxis is a form commonly found in nature that is derived from the Fibonacci sequence. It is the inspiration for Seed Media Group’s logo, designed in 2005 by Stefan Sagmeister and recently included in the Design and the Elastic Mind exhibit at MoMA. “Much like a phyllotaxis, visualization is about both numbers and information as well as structure and form,” said Ben Fry. “It’s a reminder that beauty is derived from the intelligence of the solution.”
The full press release can be found here (PDF), and more details are forthcoming.
Some combination of internet-fed conspiracy theorists and Google Earthlings (lings that use Google Earth) were abuzz last week with an odd image find, possibly representing the lost city of Atlantis:
These hopes were later dashed (or perhaps only fed further) when the apparition was denied in a post on the Official Google Blog crafted by two of the gentlemen involved in the data collection for Google Ocean. The post is fascinating as it describes much of the process that they use to get readings of the ocean floor. They explain how echosounding (soundwaves bounced into the depths) is used to determine distance, and when that’s not possible, they actually use the sea level itself:
Above large underwater mountains (seamounts), the surface of the ocean is actually higher than in surrounding areas. These seamounts actually increase gravity in the area, which attracts more water and causes sea level to be slightly higher. The changes in water height are measurable using radar on satellites. This allows us to make a best guess as to what the rest of the sea floor looks like, but still at relatively low resolutions (the model predicts the ocean depth about once every 4000 meters). What you see in Google Earth is a combination of both this satellite-based model and real ship tracks from many research cruises (we first published this technique back in 1997).
How great is that? The water actually reveals shapes beneath because of gravity’s rearrangement of the ocean surface.
A more accurate map of the entire ocean would require a bit more effort:
…we could map the whole ocean using ships. A published U.S. Navy study found that it would take about 200 ship-years,meaning we’d need one ship for 200 years, or 10 ships for 20 years, or 100 ships for two years. It costs about $25,000 per day to operate a ship with the right mapping capability, so 200 ship-years would cost nearly two billion dollars.
Holy crap, two billion dollars? That’s real money!
That may seem like a lot of money…
Yeah, no kidding — that’s what I just said!
…but it’s not that far off from the price tag of, say, a new sports stadium.
Oh.
You mean this would teach us more than New Yorkers will learn from the Meadowlands Stadium debacle, beyond “the Jets still stink” and “Eli Manning is still a weenie”? (Excellent Bob Herbert op-ed on a similar topic — the education part, not the Manning part.)
So in the end, this “Atlantis” is the result of the rounding error in the patchwork of data produced by the various measurement and tiling methods. Not as exciting as a waterlogged and trident-wielding civilization, but the remainder of the article is a great read if you’re curious about how the ocean images are collected assembled.
Passing along a call for the ACM Creativity & Cognition 2009. Sadly I’m overbooked and won’t be able to participate this year, but I attended in 2007 and found it a much more personal alternative to the more enormous ACM conferences (CHI, SIGGRAPH) without losing quality.
Everyday Creativity: Shared Languages and Collective Action
October 27-30, 2009, Berkeley Art Museum, CA, USA
Sponsored by ACM SIGCHI, in co-operation with SIGMM/ SIGART [pending approval]
Keynote Speakers
Mihaly Csikszentmihalyi Professor of Psychology & Management, Claremont Graduate University, USA
JoAnn Kuchera-Morin Director, Allosphere Research Laboratory, California Nanosystems Institute, USA
Jane Prophet Professor of Interdisciplinary Computing, Goldsmiths University of London, UK
Call for Participation
Full Papers, Art Exhibition, Live Performances, Demonstrations, Posters, Workshops, Tutorials, Graduate Symposium
Creativity is present in all we do. The 7th Creativity and Cognition Conference (CC09) embraces the broad theme of Everyday Creativity. This year the conference will be held at the Berkeley Art Museum (CA, USA), and asks: How do we enable everyone to enjoy their creative potential? How do our creative activities differ? What do they have in common? What languages can we use to talk to each other? How do shared languages support collective action? How can we incubate innovation? How do we enrich the creative experience? What encourages participation in everyday creativity?
The Creativity and Cognition Conference series started in 1993 and is sponsored by ACM SIGCHI. The conference provides a forum for lively interdisciplinary debate exploring methods and tools to support creativity at the intersection of art and technology. We welcome submissions from academics and practitioners, makers and scientists, artists and theoreticians. This year’s broad theme of Everyday Creativity reflects the new forms of creativity emerging in everyday life, and includes topics of:
Collective creativity and creative communities
Shared languages and Participatory creativity
Incubating creativity and supporting Innovation
DIY and folk creativity
Democratising creativity
New materials for creativity
Enriching the collaborative experience
We welcome the following forms of submission:
Empirical evaluations by quantitative and qualitative methods
In-depth case studies and ethnographic analyses
Reflective and theoretical accounts of individual and collaborative practice
Principles of interaction design and requirements for creativity support tools
Educational and training methods
Interdisciplinary methods, and models of creativity and collaboration
Analyses of the role of technology in supporting everyday creativity
The Berkeley Art Museum should be a great venue too.
Yearly vaccination is currently needed because different strains of the virus circulate around the world regularly, owing to the germs’ rapidly changing genetic makeup. But the researchers reported yesterday that they had found one pocket of the virus that appears to remain static in multiple strains, making it an attractive target for a vaccine, as well as drugs.
And instead of fighting the primary part virus head on, you figure out a way to attack a portion that does not mutate in the weaker part and neutralize it:
Most vaccines work by revving up the body’s disease-fighting cells, helping them to recognize and rapidly neutralize invading germs. The researchers realized that the disease fighters generated by existing flu vaccines – which contain killed or weakened whole viruses – head straight toward the biggest target, the globular head. It is, in effect, a Trojan horse that prevents the body’s immune system from directing more of its firepower toward the stalk of the [virus], where the scientists found the pocket that was so static. That site contains machinery that lets the virus penetrate human cells.
A vaccine is a way off, but they say it should be possible to make a drug that helps the body create antibodies to fight off the flu sooner than that. Incredible work.
This month’s pirate reference comes to us by way of the theory of the Flying Spaghetti Monster. The theory was first introduced in an open letter from Bobby Henderson to the Kansas State Board of Education after deciding that creationism must be taught alongside the theory of evolution. I had disregarded the Spaghetti Monster as a heavy-handed response to the hard-headed, but had missed this important bit of context:
You may be interested to know that global warming, earthquakes, hurricanes, and other natural disasters are a direct effect of the shrinking numbers of Pirates since the 1800s. For your interest, I have included a graph of the approximate number of pirates versus the average global temperature over the last 200 years. As you can see, there is a statistically significant inverse relationship between pirates and global temperature.
A stunning find! And like an overly literal translation of the bible, so accurate — except when it’s not. The horizontal scale, as Edward Tufte would say, “repays careful study.”
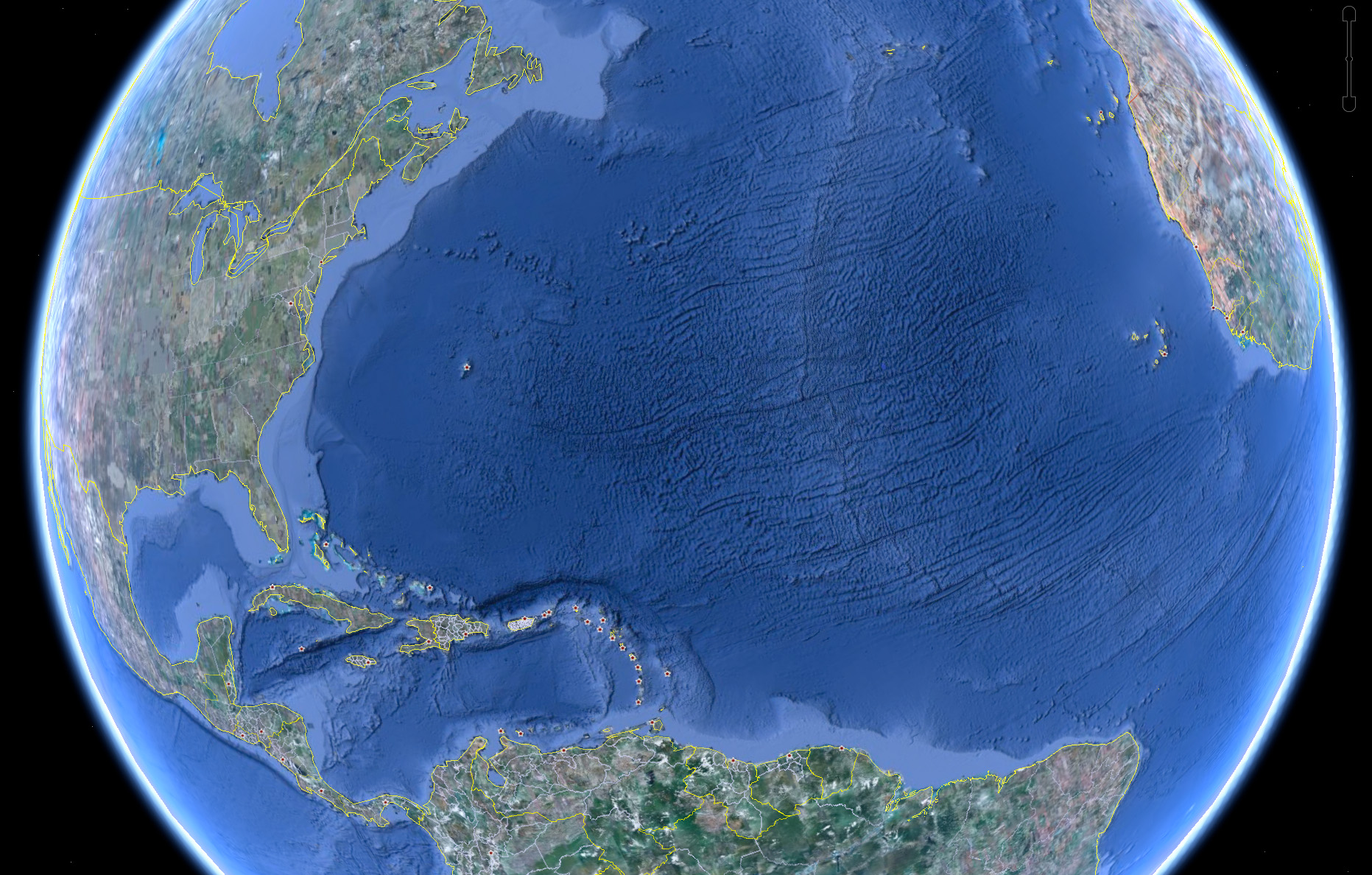
I wrote about my excitement over the rumor that Google was going under back in April, but now it has officially happened — the Ocean has arrived as part of Google Earth:
Look at those trenches! And now you can use the Google Earth software to fly through the area in the middle of the Atlantic where some god has decided to begin peeling the globe like an orange.
I’m waiting for the day (presumably a few years from now) that this feature includes other major bodies of water, revealing the hidden shapes beneath the surface of lakes or rivers that you know well from above. The physical relief version, that is. I’ll pass on the underwater Google Street View with their privacy-invading minisubs sticking their nose in everyone’s business.
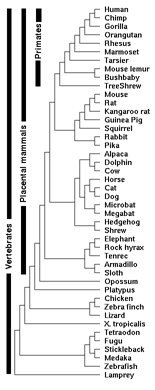
We are pleased to announce the release of a new Conservation track based on the human (hg18) assembly. This track shows multiple alignments of 44 vertebrate species and measurements of evolutionary conservation using two methods (phastCons and phyloP) from the PHAST package, for all species (vertebrate) and two subsets (primate and placental mammal). The multiple alignments were generated using multiz and other tools in the UCSC/Penn State Bioinformatics comparative genomics alignment pipeline. Conserved elements identified by phastCons are also displayed in this track. For more details, please visit the track description page…
Would someone tell me how this happened? We were the fucking vanguard of shaving in this country. The Gillette Mach3 was the razor to own. Then the other guy came out with a three-blade razor. Were we scared? Hell, no. Because we hit back with a little thing called the Mach3Turbo. That’s three blades and an aloe strip. For moisture. But you know what happened next? Shut up, I’m telling you what happened—the bastards went to four blades. Now we’re standing around … selling three blades and a strip. Moisture or no, suddenly we’re the chumps. Well, fuck it. We’re going to five blades.
Conservation tracks in the human genome are simply additional lines of annotation shown alongside the human DNA sequence. The lines show identical areas of near-similar DNA found in other species (in this case 44 vertebrates). In the past we might have looked at two, three, seven, maybe a dozen different species in a row. UCSC had actually been up to 27 different species at a time before they took the extra push over the cliff to 44.
As it turns out, just sequencing the human genome isn’t all that interesting. It only starts to get interesting in the context of other genomes from other species. With multiple species, the data can be compared and evolutionary trees drawn. We can take an organism that we know a lot about — say the fruitfly — and compare its genes (which have been studied extensively) to the genetic code of humans (who have been studied less), and we can look for similar regions. For instance, the HOX family of genes is involved in structure and limb development. A similar region can be found in humans, insects, and many things in between. How cool is that?
Further, how about all that “junk” DNA? A particular portion of DNA might have no known function, but if you find an area where the data matches (is conserved) with another species, then it might not be quite as irrelevant as previously thought (and for the record, the term junk is only used in the media). If you see that it’s highly conserved (a large percentage is identical) across many different species, then you’re probably onto something, and it’s time to start digging further.
Spending time with data like this really highlights the silliness of anti-evolution claims. It’s tough to argue with being able to see it. Unfortunately most of the work I’ve done in this area isn’t documented properly, though you can see human/chimp/dog/mouse alignments in this genome browser, a dozen mammals aligned in this illustration, or humans and chimps in this piece.
As an aside, a few months after the Onion article, Gillette really did go to five blades with their Fusion razor. And happily, the (real) CEO speaks with the same bravado as the earlier editorial:
“The Schick launch has nothing to do with this, it’s like comparing a Ferrari to a Volkswagen as far as we’re concerned,” Chairman, President and Chief Executive James Kilts, told Reuters.
Beneath a pile of 1099s, I found myself distracted still thinking about the logo colors and proportions seen in the previous post. This led to a diversion to extract the colors from the Super Bowl logos and depict them according to their usage. The colors are counted up and laid out using a Treemap.
The result for all 43 Super Bowl logos, using the same layout as the previous image:
A few of the typical pairs, starting with 2001:
See all of the pairings here. Some notes about what’s mildly clever, and the less so:
The empty space (white areas or transparent background) is subtracted from the logo, and the code tries to size the Treemap according to the aspect ratio of the original image, so that when seen adjacent the logo, things look balanced (kinda).
The code is a simple adaptation of the Treemap project in Chapter 7 of Visualizing Data.
Unfortunately, I could not find vector images (for all of the games, at least), which means the colors in the original images are not pure. For instance, edges of a solid blue color will have light blue edges because of smoothing (anti-aliasing). This makes it difficult to accurately figure out what’s a real color and what isn’t. Sometimes the fuzzy edge colors are correctly removed, other times not so much. Even worse, it may even remove legitimate colors that are used in less than 4-5% of the image.
The color quantization isn’t good. On a few, it’s bad, and causes a few similar colors to disappear.
All the above could be fixed, but taxes are more important than non-representational art. (That’s not a blanket statement — just for me this evening.)
And finally, I don’t honestly think there’s any relationship between a software algorithm for data visualization and the work of an artist like Piet Mondrian. But I do love the idea of a Dutch painter from the De Stijl movement making his way through the turnstiles at Raymond Jones Stadium.
The original article cites how the logos reflect the evolution and growth of the league. Which makes sense, you can see that it was more than fifteen years before it moved from just a logotype to a fully branded extravaganza. Or that in its first year it wasn’t the Super Bowl at all, and instead billed as “The First World Championship Game of the American Football Conference versus the National Football Conference,” a title that sounds great in a late-60s broadcaster voice (try it, you’ll like it), but was still shortened to the neanderthal “First World World Championship Game AFC vs NFC” for the logo, before it was renamed the “Super Bowl” the following year. (You can stop repeating the name in the broadcaster voice now, your officemates are getting annoyed.)
The similarities in the coloring are perhaps more interesting than the differences, though the general Americana obsession of the constant blue/red coloring is unsurprising, especially when you recall that some of the biggest perennial ad buyers (Coke, Pepsi, Budweiser) also share red, white, and blue labels. I’m guessing that the heavy use of yellow in the earlier logos had more to do with yellow looking good against a background when used for broadcast.
Or maybe not — like any good collection, there’s plenty to speculate about and many hypotheses to be drawn — and the investigation is more interesting for the exercise.
I’m often asked about sonification—instead of visualization, turning data into audio—but I’ve never pursued it because there are other things that I’m more curious about. The bigger issue is that I was concerned that audio would require even more of a trained ear than a visualization (according to some) requires a trained eye.
Johannes, time to book your ticket to IEEE InfoVis.
My opinion of Songsmith is shifting — while it’s generally presented as a laughingstock, catastrophic failure, or if nothing else, a complete embarrassment (especially for its developers slash infomercial actors), it’s really caught the imagination of a lot of people who are creating new things, even if all of them subvert the original intent of the project. (Where the original intent was to… create a tool that would help write a jingle for glow in the dark towels?)
At any rate, I think it’s achieved another kind of success, and web memes aside, I’m curious to see what actual utility comes from derivatives of the project, now that the music idea is firmly planted in peoples’ heads.
And if you stopped the video halfway through because it got a little tedious, you missed some of the good bits toward the end.
R is also the name of a popular programming language used by a growing number of data analysts inside corporations and academia. It is becoming their lingua franca partly because data mining has entered a golden age, whether being used to set ad prices, find new drugs more quickly or fine-tune financial models. Companies as diverse as Google, Pfizer, Merck, Bank of America, the InterContinental Hotels Group and Shell use it.
R is also open source, another focus of the article, which includes quoted gems such as this one from commercial competitor SAS:
“I think it addresses a niche market for high-end data analysts that want free, readily available code,” said Anne H. Milley, director of technology product marketing at SAS. She adds, “We have customers who build engines for aircraft. I am happy they are not using freeware when I get on a jet.”
Pure gold: free software is scary software! And freeware? Is she trying to conflate R with free software downloads from CNET?
Truth be told, I don’t think I’d want to be on a plane that used a jet engine designed or built with SAS (or even R, for that matter). Does she know what her product does? (A hint: It’s a statistics package. You might analyze the engine with it, but you don’t use it for design or construction.)
For those less familiar with the project, some examples:
…companies like Google and Pfizer say they use the software for just about anything they can. Google, for example, taps R for help understanding trends in ad pricing and for illuminating patterns in the search data it collects. Pfizer has created customized packages for R to let its scientists manipulate their own data during nonclinical drug studies rather than send the information off to a statistician.
At any rate, many congratulations to Robert Gentleman and Ross Ihaka, the original creators, for their success. It’s a wonderful thing that they’re making enough of a rumpus that a stats package is being covered in a mainstream newspaper.
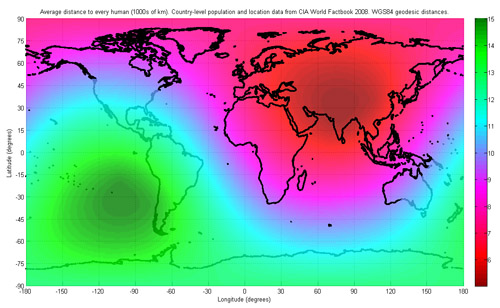
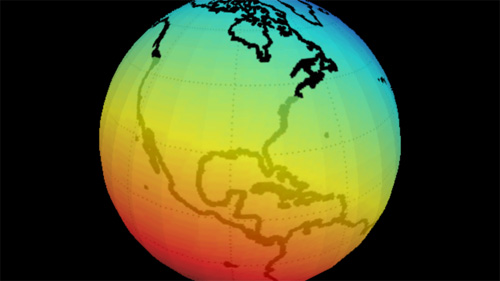
Eugene Kuo sends a link to the Wikipedia article on center of population, an awkward term for the middlin’ place of all the people in a region. Calculation can be tricky because the Earth is round (what!?) and the statistical hooey that goes into determining a proper distance metric. The article includes a heat map of world population:
…the world’s center of population is found to lie “at the crossroads between China, India, Pakistan and Tajikistan”, with an average distance of 5,200 kilometers (3,200 mi) to all humans…
Though sadly, the map also uses a strange color scale for the heat map, with blue the area of greatest density, and red (traditionally the “important” end of the scale) as the least populated area. Even shifting the colors helps a bit, at least in terms of highlighting the correct area:
Though the shift is of questionable accuracy, and the bright green still draws too much attention, as does the banding in the middle of the Atlantic.
Outside of musing for your own edification, practical applications of calculating a population’s center include:
…locating possible sites for forward capitals, such as Brasilia, Astana or Austin. Practical selection of a new site for a capital is a complex problem that depends also on population density patterns and transportation networks.
Check the article for more about centers of various countries, including the United States:
The mean center of United States population has been calculated for each U.S. Census since 1790. If the United States map were perfectly balanced on a point, this point would be its physical centroid. Currently this point is located in Phelps County, Missouri, in the east-central part of the state. However, when Washington, D.C. was chosen as the federal capital of the United States in 1790, the center of the U.S. population was in Kent County, Maryland, a mere 47 miles (76 km) east-northeast of the new capital. Over the last two centuries, the mean center of United States population has progressed westward and, since 1930, southwesterly, reflecting population drift.
For added fun, I’ve created an interactive version of the map, based on a Processing example. (Though it took me longer to write the credits for the adaptation than to actually assemble it — thanks for all those who contributed little bits to it.)
Back in December (or maybe even November… sorry, digging out my inbox this morning) Amazon announced the availability of public data sets for their Elastic Compute Cloud platform:
Previously, large data sets such as the mapping of the Human Genome and the US Census data required hours or days to locate, download, customize, and analyze. Now, anyone can access these data sets from their Amazon Elastic Compute Cloud (Amazon EC2) instances and start computing on the data within minutes. Users can also leverage the entire AWS ecosystem and easily collaborate with other AWS users. For example, users can produce or use prebuilt server images with tools and applications to analyze the data sets. By hosting this important and useful data with cost-efficient services such as Amazon EC2, AWS hopes to provide researchers across a variety of disciplines and industries with tools to enable more innovation, more quickly.
The current lists includes ENSEMBL (550 GB), GenBank (250 GB), various collections from the US Census (about 500 GB), and a handful of others (with more promised). I’m excited about the items under the “Economy” heading, since lots of that information has to date been difficult to track down in one place and in a single format.
While it may be possible to download these as raw files from FTP servers from their original sources, it’s already set up for you, rather than running rsync or ncftp for twenty-four hours, then spending an afternoon setting up a Linux server with MySQL and lots of big disk space, and dealing with various issues regarding versions of Apache, MySQL, PHP, different Perl modules to be installed, permissions to be fixed, etc. etc. (Can you tell the pain is real?)
As I understand it, you start with a frozen version of the database, then import that into your own workspace on AWS, and pay only for the CPU time, storage, and bandwidth that you actually use. Pricing details are here, but wear boots — there’s a lotta cloud marketingspeak to wade through.
An email regarding the last post, answering some of the questions about success and popularity of management games. Andrew Walkingshaw writes:
The short answer to this is “yes” – football (soccer) management games are a very big deal here in Europe. One of the major developers is Sports Interactive, (or at Wikipedia) with their Championship Manager/Football Manager series: they’ve been going over fifteen years now.
And apparently the games have even been popular since the early 80s. I found this bit especially interesting:
Fantasy soccer doesn’t really work – the game can’t really be quantified in the way NFL football or baseball can – so it could be that these games’ popularity comes from filling the same niche as rotisserie baseball does on your side of the Atlantic.
Which suggests a more universal draw to the numbers game or statistics competition that gives rise to fantasy/rotisserie leagues. The association with sports teams gives it broader appeal, but at its most basic, it’s just sports as a random number generator.
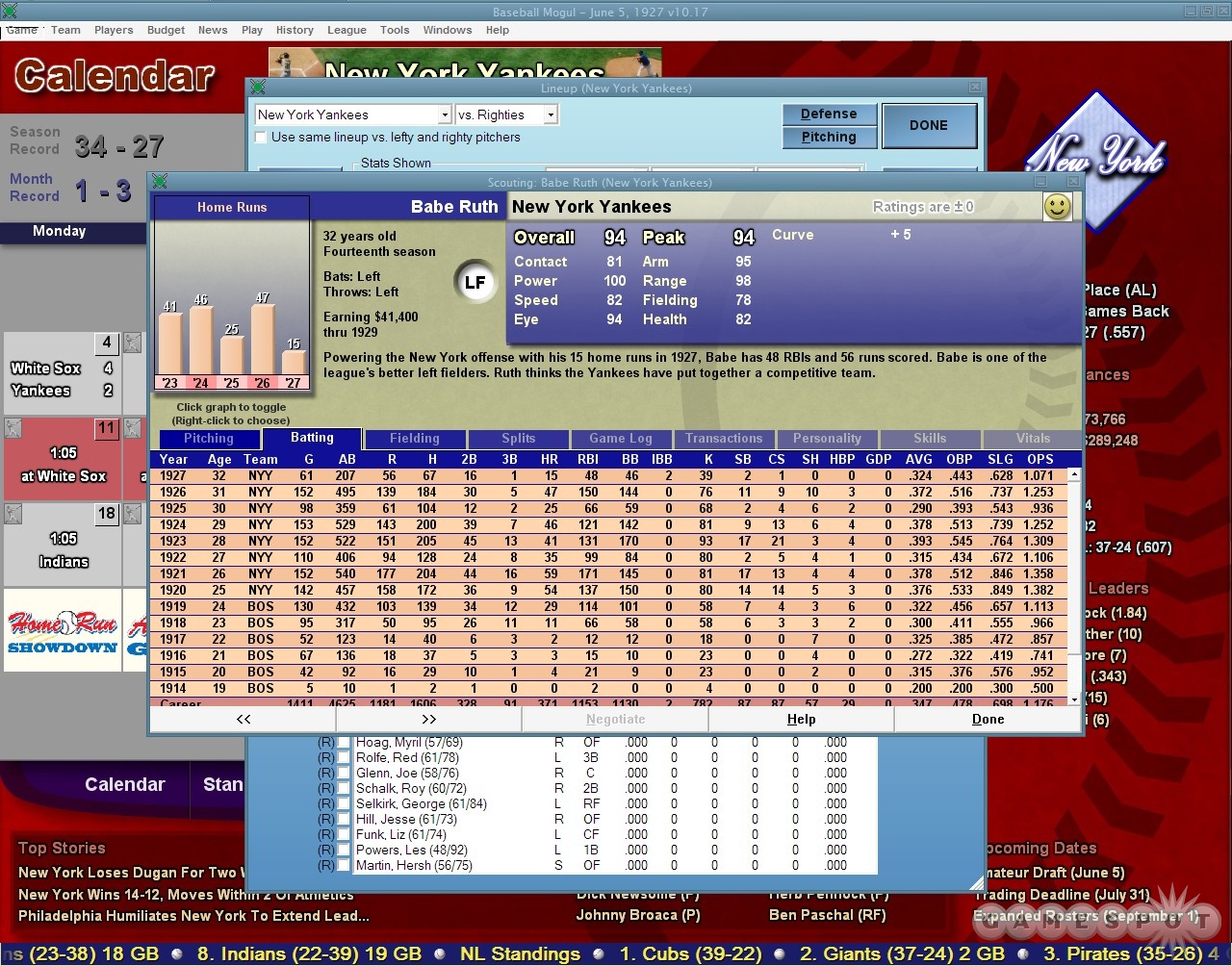
Some further digging yesterday also turned up Baseball Mogul 2008 (and the 2009 Edition). The interface seems closer to a bad financial services app (bad in this case just means poorly designed, click the image above for a screenshot), which is the opposite direction of what I’m interested in, but at least gives us another example. Although this one also seems to have reviewed better than the game from the previous post.
Via News.com, the peculiar story of MLB Front Office Manager, a sports simulation game in which you play the general manager of a major league baseball team. Daniel Terdiman writes:
The new game — which is unlike any baseball video game I’ve ever seen — has perhaps the perfect pitchman, Oakland A’s General Manager Billy Beane. For those not familiar with him, the game probably won’t mean much, since as the main subject of Michael Lewis’ hit book, Moneyball, Beane has long been considered the most cerebral and efficient guy putting contending baseball teams on the field.
This caught my eye because of its focus on the numbers, and how you’d pull that off in the context of a console game.
As you may imagine, FOM’s interface is menu heavy, providing access to the various statistical metrics and trends to keep you apprised as general manager. What is surprising is that FOM manages to bring this depth to the console as well as the PC. While other console-based franchise management titles have struggled to create effective navigation tools, FOB’s vertical menu interface is both clean and intuitive without compromising the depth one would expect from a game in this genre. Top-level categories include submenus (many of which include further submenus) similar to navigating a sports Web site.
Other reviews seem to be less charitable, but I’m less interested in the game itself than the curiosity that it exists in the first place. GameSpot describes the audience:
By 2K’s own admission, the game targets a specific niche: the roughly 3.5 million participants of Fantasy Baseball leagues. It is 2K’s hope that this hardcore baseball audience, many of whom spend two to three hours every day managing their fantasy rosters, will see FOM as a convenient alternative (or even a complement, assuming those individuals forgo sleep).
So it’s a niche, as would be expected. But I’m curious about a handful of issues, a combination of not knowing much about gaming, mixed with a fascination for what gaming means for interfaces:
Could this be done properly, to a point where a game like this is a wider success? The niche audience is interesting at first, but is it possible to take a numbers game to a broader audience than that?
Has anyone already had success doing that?
Are there methods for showing complex numbers, data, and stats that have been used in (particularly console) games that are more effective than typical information dashboards used by, say, corporations?
The combination of having a motivated user who is willing to put up with the numbers suggests that some really interesting things could be done. And because the interface has to be optimized for the limited interaction afforded by a handheld controller (if played on a console) suggests that the implementation would also need to be clever.
If you have any insight, please drop me a line. Or you can continue to speculate for yourself while enjoying the promotional video below with the most fantastically awful background music I’ve heard since Microsoft Songsmith appeared a little while ago.
OpenStreetMap is a wiki-style map of the world and this animation displays a white flash each time a way is entered or updated. Some edits are a result of a physical local survey by a contributor with a GPS unit and taking notes, other edits are done remotely using aerial photography or out-of-copyright maps, and some are bulk imports of official data.
Simple idea but really elegant execution. Created by ITO.
That we are in the midst of crisis is now well understood. Our nation is at war, against a far-reaching network of violence and hatred. Our economy is badly weakened, a consequence of greed and irresponsibility on the part of some, but also our collective failure to make hard choices and prepare the nation for a new age. Homes have been lost; jobs shed; businesses shuttered. Our health care is too costly; our schools fail too many; and each day brings further evidence that the ways we use energy strengthen our adversaries and threaten our planet.
These are the indicators of crisis, subject to data and statistics. Less measurable but no less profound is a sapping of confidence across our land – a nagging fear that America’s decline is inevitable, and that the next generation must lower its sights.
For the politically-oriented math geek in me, his mention of statistics stood out: we now have a president who can actually bring himself to reference numbers and facts. I searched for other mentions of “statistics” in previous inaugural speeches and found just a single, though oddly relevant, quote from William Howard Taft in 1909:
The progress which the negro has made in the last fifty years, from slavery, when its statistics are reviewed, is marvelous, and it furnishes every reason to hope that in the next twenty-five years a still greater improvement in his condition as a productive member of society, on the farm, and in the shop, and in other occupations may come.
Progress indeed. (And what’s the term for that? A surprising coincidence? Irony? Is there a proper term for such a connection? Perhaps a thirteen letter German word along the lines of schadenfreude?)
And it’s such a relief to see the return of science:
For everywhere we look, there is work to be done. The state of the economy calls for action, bold and swift, and we will act – not only to create new jobs, but to lay a new foundation for growth. We will build the roads and bridges, the electric grids and digital lines that feed our commerce and bind us together. We will restore science to its rightful place, and wield technology’s wonders to raise health care’s quality and lower its cost. We will harness the sun and the winds and the soil to fuel our cars and run our factories. And we will transform our schools and colleges and universities to meet the demands of a new age. All this we can do. And all this we will do.
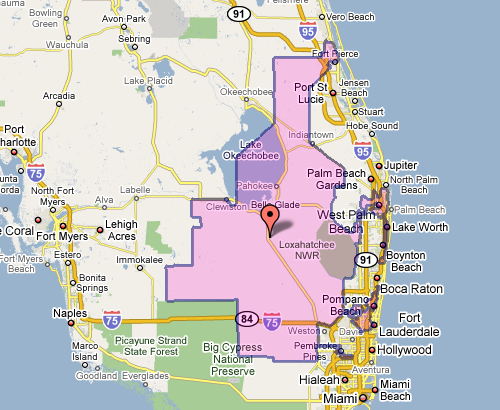
An interesting article from Slate about a session at the Joint Mathematics Meeting that discussed mathematical solutions and proposals to undo the problem of gerrymandered congressional districts. That is, politicians in congress having the ability to draw an outline around the group of people they want to represent (which is based on how likely they are to vote for said politician’s re-election). The resulting shapes are often comical, insofar as you’re willing to be cheerful in a “politics is perpetually broken and corrupt” kind of way. Chris Wilson writes:
It’s tough to find many defenders of the status quo, in which a supermajority of House seats are noncompetitive. (Congressional Quarterlyranked 324 of the 435 seats as “safe” for one party or the other in 2008.) The mathematicians—and social scientists and lawyers—who gathered to discuss the subject Thursday are certain there’s a better way to do it. They just haven’t quite figured out what it is.
The meeting also seemed to include a contest (knock down, drag out, winner take pocket protector) between the presenters each trying to one-up each other for worst district. For instance, Florida’s 23rd, provided by govtrack.us:
Which doesn’t seem awful at first, until you see the squiggle up the coast. Or Pennsylvania’s 12th, which Wilson describes as “an anchor glued to a sea anemone.”
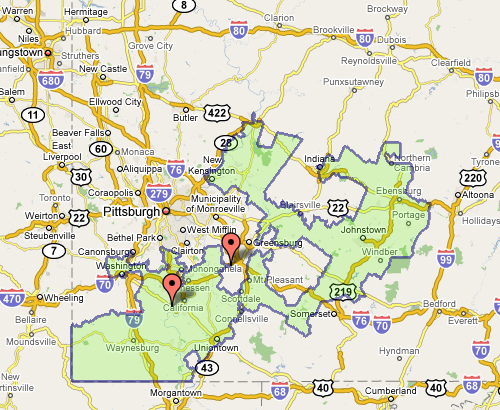
Fixing the problem is difficult, but sometimes there are elegant and straightforward metrics that get you closer to a solution:
The most interesting proposal of the afternoon came from a Caltech grad student named Alan Miller, who proposed a simple test: If you take two random people in a district, what are the odds that one can walk in a straight line to the other without ever leaving the district? (Actually, it’s without leaving the district while remaining in the state, so as not to penalize districts like Maryland’s 6th, which has to account for Virginia’s hump.) This rewards neat, simple shapes. But it penalizes districts like Maryland’s 3rd, which looks like something out of Kandinsky’s Improvisation 31.
This turns the issue into something directly testable (two residents and their path) for which we can calculate a probability — the sort of thing statisticians love (because it can be measured). Given this criteria (and others like it) for congressional district godliness, another proposal was a kind of Netflix Prize for redistricting, where groups could compete to develop the best redistricting algorithm. Such an algorithm would seek to remove the (bipartisan) mischief by limiting human intervention.
The original article also includes a slide show of particularly heinous district shapes. And as an aside, the images above, while enormously useful, illustrate part of my beef with mash-ups: Google Maps was designed as a mapping application, not a mapping-with-stuff-on-it application. So when you add data to the map image — itself a completed design —you throw off that balance. It’s difficult to read the additional information (the district area), and the information that’s there (the map coloring, specific details of the roads) is more than necessary for this purpose.
Visualizing Data is my 2007 book about computational information design. It covers the path from raw data to how we understand it, detailing how to begin with a set of numbers and produce images or software that lets you view and interact with information. When first published, it was the only book(s) for people who wanted to learn how to actually build a data visualization in code.
The text was published by O’Reilly in December 2007 and can be found at Amazon and elsewhere. Amazon also has an edition for the Kindle, for people who aren’t into the dead tree thing. (Proceeds from Amazon links found on this page are used to pay my web hosting bill.)
The book covers ideas found in my Ph.D. dissertation, which is the basis for Chapter 1. The next chapter is an extremely brief introduction to Processing, which is used for the examples. Next is (chapter 3) is a simple mapping project to place data points on a map of the United States. Of course, the idea is not that lots of people want to visualize data for each of 50 states. Instead, it’s a jumping off point for learning how to lay out data spatially.
The chapters that follow cover six more projects, such as salary vs. performance (Chapter 5), zipdecode (Chapter 6), followed by more advanced topics dealing with trees, treemaps, hierarchies, and recursion (Chapter 7), plus graphs and networks (Chapter 8).
This site is used for follow-up code and writing about related topics.


 I was in the midst of starting a new post in January so I failed to make a post about it at the time, but
I was in the midst of starting a new post in January so I failed to make a post about it at the time, but 




 Liskov’s early innovations in software design have been the basis of every important programming language since 1975, including Ada, C++, Java and C#.
Liskov’s early innovations in software design have been the basis of every important programming language since 1975, including Ada, C++, Java and C#. The unit’s research arm, the Phyllotaxis Lab, will work to advance the field of data visualization and will undertake research and experimental design work. The Lab will partner with academic institutions around the world and will provide education on the field of data visualization.
The unit’s research arm, the Phyllotaxis Lab, will work to advance the field of data visualization and will undertake research and experimental design work. The Lab will partner with academic institutions around the world and will provide education on the field of data visualization.
 Creativity is present in all we do. The 7th Creativity and Cognition Conference (CC09) embraces the broad theme of Everyday Creativity. This year the conference will be held at the Berkeley Art Museum (CA, USA), and asks: How do we enable everyone to enjoy their creative potential? How do our creative activities differ? What do they have in common? What languages can we use to talk to each other? How do shared languages support collective action? How can we incubate innovation? How do we enrich the creative experience? What encourages participation in everyday creativity?
Creativity is present in all we do. The 7th Creativity and Cognition Conference (CC09) embraces the broad theme of Everyday Creativity. This year the conference will be held at the Berkeley Art Museum (CA, USA), and asks: How do we enable everyone to enjoy their creative potential? How do our creative activities differ? What do they have in common? What languages can we use to talk to each other? How do shared languages support collective action? How can we incubate innovation? How do we enrich the creative experience? What encourages participation in everyday creativity?
 Conservation tracks in the human genome are simply additional lines of annotation shown alongside the human DNA sequence. The lines show identical areas of near-similar DNA found in other species (in this case 44 vertebrates). In the past we might have looked at two, three, seven, maybe a dozen different species in a row. UCSC had actually been up to 27 different species at a time before they took the extra
Conservation tracks in the human genome are simply additional lines of annotation shown alongside the human DNA sequence. The lines show identical areas of near-similar DNA found in other species (in this case 44 vertebrates). In the past we might have looked at two, three, seven, maybe a dozen different species in a row. UCSC had actually been up to 27 different species at a time before they took the extra 




 Article from the New York Times
Article from the New York Times