Before I even had a chance to write about personal genomics companies 23andMe, Navigenics, and deCODEme, Forbes reports that the California Health Department is looking to shut them down:
This week, the state health department sent cease-and-desist letters to 13 such firms, ordering them to immediately stop offering genetic tests to state residents.
Because of advances in genotyping, it’s possible for companies to detect changes from half a million data points (or soon, a million) of a person’s genome. The idea behind genotyping is that you look only for the single letter changes (SNPs) that are more likely to be unique between individuals, and then use that to create a profile of similarities and differences. So companies have sprung up, charging $1000 (ok, $999) a pop to decode these bits of your genome. It can then tell you some basic things about ancestry, or maybe a little about susceptibility for certain kinds of diseases (those that have a fairly simple genetic makeup—of which there aren’t many, to be sure).
Lea Brooks, spokesperson for the California Health Department, confirmed for Wired that:
…the investigation began after “multiple” anonymous complaints were sent to the Health Department. Their researchers began with a single target but the list of possible statute violators grew as one company led to another.
Listen folks, this is not just one California citizen, but two or more anonymous persons! Perhaps one of them was a doctor or insurance firm who have been neglected their cut of the $1000:
One controversy is that some gene testing Web sites take orders directly from patients without a doctor’s involvement.
Well now, that is a controversy! Genetics has been described as the future of medicine, and yet traditional drainers of wallets (is drainer a word?) in the current health care system have been sadly neglected. The Forbes article also describes the nature of the complaints:
The consumers were unhappy about the accuracy [of the tests] and thought they cost too much.
California residents will surely be pleased that the health department is taking a hard stand on the price of boutique self-testing. As soon as they finish off these scientifimagical “genetic test” goons, we could all use a price break on home pregnancy tests.
 And as to the accuracy of, or what can be ascertained from such tests? That’s certainly been a concern of the genetics community, and in fact 23andme has “admitted its tests are not medically useful, as they represent preliminary findings, and so are merely for educational purposes.” Which is perfectly clear to someone visiting their site, however that presents a bigger problem:
And as to the accuracy of, or what can be ascertained from such tests? That’s certainly been a concern of the genetics community, and in fact 23andme has “admitted its tests are not medically useful, as they represent preliminary findings, and so are merely for educational purposes.” Which is perfectly clear to someone visiting their site, however that presents a bigger problem:
“These businesses are apparently operating without a clinical laboratory license in California. The genetic tests have not been validated for clinical utility and accuracy,” says Nickel.
So an accurate, clinical-level test is illegal. But a less accurate, do-it-yourself (without a doctor) test is also illegal. And yet, California’s complaint gets more bizarre:
“And they are scaring a lot of people to death.”
Who? The people who were just complaining about the cost of the test? That’s certainly a potential problem if you don’t do testing through a doctor—and in fact, it’s a truly significant concern. But who purchases a $999 test from a site with the cartoon characters seen above to check for Huntington’s disease?
And don’t you think if “scaring people” were the problem, wouldn’t the papers and the nightly news be all over it? The only thing they love more than a new scientific technology that’s going to save the world is a new scientific technology to be scared of. Ooga booga! Fearmongering hits the press far more quickly than it does the health department, so this particular line of argument just sounds specious.
The California Health Department does an enormous disservice to the debate of a complicated issue by mixing several lines of reasoning which taken as a whole simply contradict one another. The role of personal genetic testing in our society deserves a debate and consideration; I thought I would be able to post about that part first, but instead the CA government beat me to the dumb stuff.
Thomas Goetz, deputy editor at Wired has had two such tests (clearly not unhappy with the price), and angrily responds “Attention, California Health Department: My DNA Is My Data.” It’s not just those anonymous Californians who are wound up about genetic testing, he’s writing his sternly worded letter as we speak:
This is my data, not a doctor’s. Please, send in your regulators when a doctor needs to cut me open, or even draw my blood. Regulation should protect me from bodily harm and injury, not from information that’s mine to begin with.
Are angry declarations of ownership of one’s health data a new thing? It’s not like most people fight for their doctor’s office papers, or even something as simple as a fingerprint, this way.
It’ll be interesting to see how this shakes out. Or it might not, since it will probably consist of:
- A settlement by the various companies to continue doing business.
- Some means of doctors and insurance companies getting paid (requiring a visit, at a minimum).
- People trying to circumvent #2 (see related topics filed under “H” for Human Growth Hormone).
- An entrepreneur figures out how to do it online and in a large scale fashion (think WebMD), turning out new hoards of “information” seeking hypochondriacs to fret about their 42% potential alternate likelihood maybe chance of genetic malady. (You have brain cancer too!? OMG!)
- If this hits mainstream news, will people hear about the outcome of #1, or will there be an assumption that “personal genetic tests are illegal” from here on out? How skittish will this make investors (the Forbes set) about such companies?
Then again, I’ve already proven myself terrible at predicting the future. But I’ll happily enjoy the foolishness of the present.


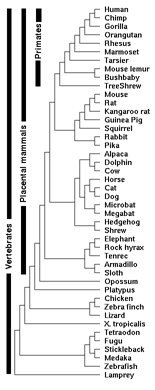 Conservation tracks in the human genome are simply additional lines of annotation shown alongside the human DNA sequence. The lines show identical areas of near-similar DNA found in other species (in this case 44 vertebrates). In the past we might have looked at two, three, seven, maybe a dozen different species in a row. UCSC had actually been up to 27 different species at a time before they took the extra
Conservation tracks in the human genome are simply additional lines of annotation shown alongside the human DNA sequence. The lines show identical areas of near-similar DNA found in other species (in this case 44 vertebrates). In the past we might have looked at two, three, seven, maybe a dozen different species in a row. UCSC had actually been up to 27 different species at a time before they took the extra 