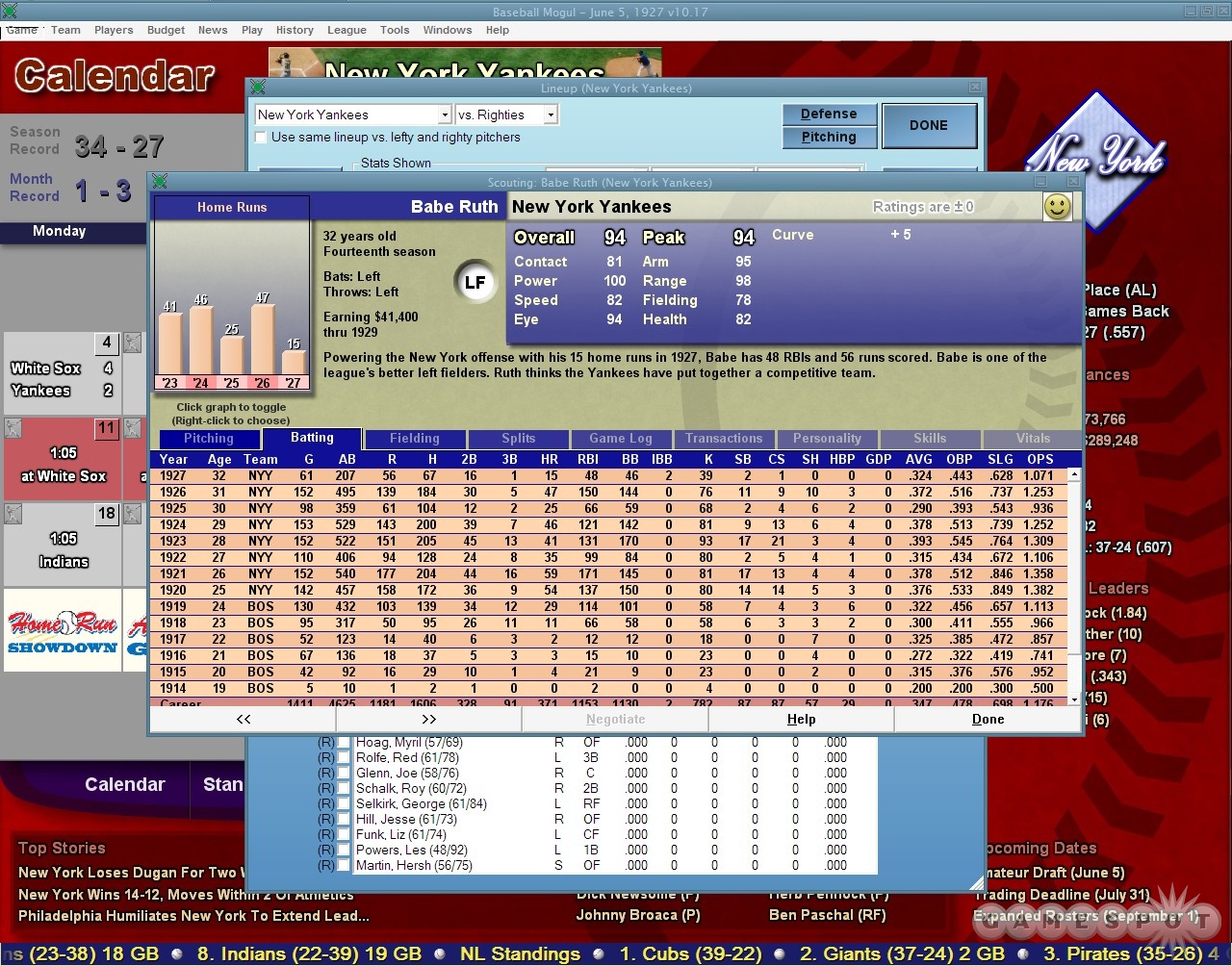
Computers are really good at repetitive work. You can ask a computer to multiply two numbers together seven billion times and not only will it not complain, it’ll probably have seven billion answers for you a few seconds later. Ask a person to do the same thing and they’ll either walk away at the outset, realizing the ridiculousness of the task, or they’ll get through the first few tries and lose interest. But even the fact that a human can recognize the ridiculousness of the task is important. Humans are good at lots of things—like identifying a face in a crowd—that cannot be addressed by computation with the same level of accuracy.
Computers are really good at repetitive work. You can ask a computer to multiply two numbers together seven billion times and not only will it not complain, it’ll probably have seven billion answers for you a few seconds later. Ask a person to do the same thing and they’ll either walk away at the outset, realizing the ridiculousness of the task, or they’ll get through the first few tries and lose interest. But even the fact that a human can recognize the ridiculousness of the task is important. Humans are good at lots of things—like identifying a face in a crowd—that cannot be addressed by computation with the same level of accuracy.
Visualization is about the interface between what humans are good at, and what computers are good at. First, the computer can crunch all seven billion numbers, then present the results in a way that we can use our own perceptual skills to identify what’s important or interesting. (This is also why the design of a visualization is a fundamentally human task, and not something to be left to automation.)
This is also the subject of Luis von Ahn’s work at Carnegie Mellon. You’re probably familiar with CAPTCHA images—usually wavy numbers and letters that you have to discern when signing up for a webmail account or buying tickets from Ticketmaster. The acronym stands for “Completely Automated Public Turing Test to Tell Computers and Humans Apart,” a clever mouthful referring to Alan Turing’s work in discerning man or machine. (I encourage you to read about them, but this is already getting long so I won’t get into it here.)
More interesting than CAPTCHA, however, is the whole notion that’s behind it: that it’s an example of relying on humans to do what they’re best at, though it’s a task that’s difficult for computers. (Sure, in recent weeks, people have actually found ways to “break” CAPTCHAs in specific cases, but that’s not important here.) For instance, the work was extended to the Google Image Labeler, described as follows:
You’ll be randomly paired with a partner who’s online and using the feature. Over a two-minute period, you and your partner will:
- View the same set of images.
- Provide as many labels as possible to describe each image you see.
- Receive points when your label matches your partner’s label. The number of points will depend on how specific your label is.
- See more images until time runs out.
Prior to this, most image labeling systems had to do with getting volunteers to name or tag images individually. As you can imagine, the quality of tags suffer considerably because of everything from differences in how people perceive or describe what they see, to individuals who try to be a little too clever in choosing tags. With the Image Labeler game, that’s turned around backwards, where there is a motivation to use tags that match the other person, thus minimizing the previous problems. (It’s “Mechanical Turk” meets “Family Feud”.) They’ve also applied the same ideas to scanning books—where fragments of text that cannot be recognized by software are instead checked by multiple people.
More recently, von Ahn’s group has expanded these ideas in Games With A Purpose, a site that addresses these “casual games” more directly. The new site is covered in this New Scientist article, which offers additional tidbits (perspective? background? couldn’t think of the right word).
You can also watch Luis’ Google Tech Talk about Human Computation, which if I’m not mistaken, led to the Image Labeler project.
(We met Luis a couple times while at CMU and watched the Superbowl with his awesome fiancée Laura, cheering on her hometown Chicago Bears against those villainous Colts. We were happy when he received a MacArthur Fellowship for his work—just the sort of person you’d like to get such an award that highlights people who often don’t quite fit in their field.)
 Returning to the earlier argument, algorithms to identify a face in a crowd are certainly improving. But without a significant breakthrough, their usefulness will be significantly limited. One commonly hyped use for such systems is airport security. Bruce Schneier explains the problem:
Returning to the earlier argument, algorithms to identify a face in a crowd are certainly improving. But without a significant breakthrough, their usefulness will be significantly limited. One commonly hyped use for such systems is airport security. Bruce Schneier explains the problem:
Suppose this magically effective face-recognition software is 99.99 percent accurate. That is, if someone is a terrorist, there is a 99.99 percent chance that the software indicates “terrorist,” and if someone is not a terrorist, there is a 99.99 percent chance that the software indicates “non-terrorist.” Assume that one in ten million flyers, on average, is a terrorist. Is the software any good?
No. The software will generate 1000 false alarms for every one real terrorist. And every false alarm still means that all the security people go through all of their security procedures. Because the population of non-terrorists is so much larger than the number of terrorists, the test is useless. This result is counterintuitive and surprising, but it is correct. The false alarms in this kind of system render it mostly useless. It’s “The Boy Who Cried Wolf” increased 1000-fold.
Given the number of travelers at Boston Logan in 2006, that would be two “terrorists” identified per day. (And with Schneier’s one in ten million is a terrorist figure, that would be two or three terrorists per year…clearly too generous, which makes the face detection accuracy even worse than how he describes it.) I find myself thinking about the 99.99% accuracy number as I stare at the back of heads lined up at the airport security checkpoint—itself a human problem, not a computational problem.