
Postleitzahlen in Deutschland
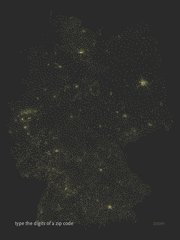 Maximillian Dornseif has adapted Zipdecode from Chapter 6 of Visualizing Data to handle German postal codes. I’ve wanted to do this myself since hearing about the OpenGeoDB data set which includes the data, but thankfully he’s taken care of it first and is sharing it with the rest of us along with his modified code.
Maximillian Dornseif has adapted Zipdecode from Chapter 6 of Visualizing Data to handle German postal codes. I’ve wanted to do this myself since hearing about the OpenGeoDB data set which includes the data, but thankfully he’s taken care of it first and is sharing it with the rest of us along with his modified code.
(The site is in German…I’ll trust any of you German readers to let me know if the site actually says that Visualizing Data is the dumbest book he’s ever read.)
Also helpful to note that he used Python for preprocessing the data. He doesn’t bother implementing a map projection, as done in the book, but the Python code is a useful example of using another language when appropriate, and how the syntax differs from Processing:
# Convert opengeodb data for zipdecode
fd = open('PLZ.tab')
out = []
minlat = minlon = 180
maxlat = maxlon = 0
for line in fd:
line = line.strip()
if not line or line.startswith('#'):
continue
parts = line.split('\t')
dummy, plz, lat, lon, name = parts
out.append([plz, lat, lon, name])
minlat = min([float(lat), minlat])
minlon = min([float(lon), minlon])
maxlat = max([float(lat), maxlat])
maxlon = max([float(lon), maxlon])
print "# %d,%f,%f,%f,%f" % (len(out), minlat, maxlat, minlon, maxlon)
for data in out:
plz, lat, lon, name = data
print '\t'.join([plz, str(float(lat)), str(float(lon)), name])
In the book, I used Processing for most of the examples (with a little bit of Perl) for sake of simplicity. (The book is already introducing a lot of new material, why hurt people and introduce multiple languages while I’m at it?) However that’s one place where the book diverges from my own process a bit, since I tend to use a lot of Perl when dealing with large volumes of text data. Python is also a good choice (or Ruby if that’s your thing), but I’m tainted since I learned Perl first, while a wee intern at Sun.
