
Visualizing Data with Portuguese and Processing.js
Very cool! Check out these implementations of several Visualizing Data examples that make use of John Resig’s Processing.js, an adaptation of the Processing API with pure JavaScript. This means running in a web browser with no additional plug-ins (no Java Virtual Machine kicking in while you take a sip of coffee—much less drain the whole cup, depending the speed of your computer). Since the first couple chapters cover straightforward, static exercises, I’d been wanting to try this, but it’s more fun when someone beats you to it. (Nothing is better than feeling like a slacker, after all.)
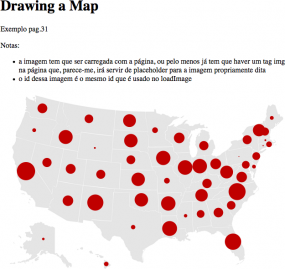 View the introductory Processing sketch from Page 22, or the map of the United States populated with random data points from Page 35.
View the introductory Processing sketch from Page 22, or the map of the United States populated with random data points from Page 35.
Babelfish translation of the page here, with choice quotes like “also the shipment of external filing-cabinets had that to be different of what was in the book.”
And the thing is, when I finished the proof of the book for O’Reilly, I had this uneasy feeling that I was shipping the wrong filing-cabinets. Particularly the external ones.
