
Subjectively Attractive Client-Side Scripted Browser-Delivered Charts and Plots
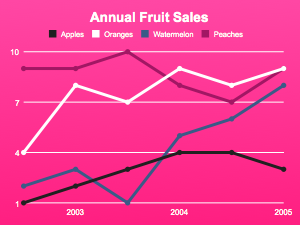 …also known as Bluff, though they call it “Beautiful Graphs in JavaScript.” And who can argue with pink?
…also known as Bluff, though they call it “Beautiful Graphs in JavaScript.” And who can argue with pink?
Bluff is a JavaScript port of the Gruff graphing library for Ruby. It is designed to support all the features of Gruff with minimal dependencies; the only third-party scripts you need to run it are a copy of JS.Class (about 2kb gzipped) and a copy of Google’s ExCanvas to support
canvasin Internet Explorer. Both these scripts are supplied with the Bluff download. Bluff itself is around 8kb gzipped.
There’s something cool (and hilarious) about the fact that even though we’re talking about bleeding edge features (decent JavaScript and Canvas support) only available in the most recent of modern browser releases, the criteria of awesomeness and usefulness is still the same as 1997 — that it’s only 8 Kb.
(The only thing that strikes me as odd, strictly from an interface perspective, is the fact that I can’t drag the “image” to the Desktop, the way that I would a JPEG or GIF image. Certainly that’s also the case for Flash and Java, but there’s something that strikes me as strange the way that JavaScript is so lightweight — part of the browser — yet the thing isn’t really “there”.)
At any rate, I’m fairly fascinated by this idea of JavaScript being a useful client-side means of generating images. Something very exciting is bound to happen.
