Computers know nothing but numbers. As humans we have varying levels of skill in using numbers, but most of the time we’re communicating with words and phrases. So in the early days of computing, the earliest software developers had to find a way to map each character—a letter Q, the character #, or maybe a lowercase b—into a number. A table of characters would be made, usually either 128 or 256 of them, depending on whether data was stored or transmitted using 7 or 8 bits. Often the data would be stored as 7 bits, so that the eighth bit could be used as a parity bit, a simple method of error correction (because data transmission—we’re talking modems and serial ports here—was so error prone).
Early on, such encoding systems were designed in isolation, which meant that they were rarely compatible with one another. The number 34 in one character set might be assigned to “b”, while in another character set, assigned to “%”. You can imagine how that works out over an entire message, but the hilarity was lost on people trying to get their work done.
In the 1960s, the American National Standards Institute (or ANSI) came along and set up a proper standard, called ASCII, that could be shared amongst computers. It was 7 bits (to allow for the parity bit) and looked like:
0 nul 1 soh 2 stx 3 etx 4 eot 5 enq 6 ack 7 bel
8 bs 9 ht 10 nl 11 vt 12 np 13 cr 14 so 15 si
16 dle 17 dc1 18 dc2 19 dc3 20 dc4 21 nak 22 syn 23 etb
24 can 25 em 26 sub 27 esc 28 fs 29 gs 30 rs 31 us
32 sp 33 ! 34 " 35 # 36 $ 37 % 38 & 39 '
40 ( 41 ) 42 * 43 + 44 , 45 - 46 . 47 /
48 0 49 1 50 2 51 3 52 4 53 5 54 6 55 7
56 8 57 9 58 : 59 ; 60 < 61 = 62 > 63 ?
64 @ 65 A 66 B 67 C 68 D 69 E 70 F 71 G
72 H 73 I 74 J 75 K 76 L 77 M 78 N 79 O
80 P 81 Q 82 R 83 S 84 T 85 U 86 V 87 W
88 X 89 Y 90 Z 91 [ 92 \ 93 ] 94 ^ 95 _
96 ` 97 a 98 b 99 c 100 d 101 e 102 f 103 g
104 h 105 i 106 j 107 k 108 l 109 m 110 n 111 o
112 p 113 q 114 r 115 s 116 t 117 u 118 v 119 w
120 x 121 y 122 z 123 { 124 | 125 } 126 ~ 127 del
The lower numbers are various control codes, and the characters 32 (space) through 126 are actual printed characters. An eagle-eyed or non-Western reader will note that there are no umlauts, cedillas, or Kanji characters in that set. (You’ll note that this is the American National Standards Institute, after all. And to be fair, those were things well outside their charge.) So while the immediate character encoding problem of the 1960s was solved for Westerners, other languages would still have their own encoding systems.
As time rolled on, the parity bit became less of an issue, and people were antsy to add more characters. Getting rid of the parity bit meant 8 bits instead of 7, which would double the number of available characters. Other encoding systems like ISO-8859-1 (also called Latin-1) were developed. These had better coverage for Western European languages, by adding some umlauts we’d all been missing. The encodings kept the first 0–127 characters identical to ASCII, but defined characters numbered 128–255.
However this still remained a problem, even for Western languages, because if you were on a Windows machine, there was a different definition for characters 128–255 than there was on the Mac. Windows used what was called Windows 1252, which was just close enough to Latin-1 (embraced and extended, let’s say) to confuse everyone and make a mess. And because they like to think different, Apple used their own standard, called Mac Roman, which had yet another colorful ordering for characters 128–255.
This is why there are lots of web pages that will have squiggly marks or odd characters where em dashes or quotes should be found. If authors of web pages include a tag in the HTML that defines the character set (saying essentially “I saved this on a Western Mac!” or “I made this on a Norwegian Windows machine!”) then this problem is avoided, because it gives the browser a hint at what to expect in those characters with numbers from 128–255.
Those of you who haven’t fallen asleep yet may realize that even 200ish characters still won’t do—remember our Kanji friends? Such languages usually encode with two bytes (16 bits to the West’s measly 8), providing access to 65,536 characters. Of course, this creates even more issues because software must be designed to no longer think of characters as a single byte.
In the very early 90s, the industry heavies got together to form the Unicode consortium to sort out all this encoding mess once and for all. They describe their charge as:
Unicode provides a unique number for every character,
no matter what the platform,
no matter what the program,
no matter what the language.
They’ve produced a series of specifications, both for a wider character set (up to 4! bytes) and various methods for encoding these character sets. It’s truly amazing work. It means we can do things like have a font (such as the aptly named Arial Unicode) that defines tens of thousands of character shapes. The first of these (if I recall correctly) was Bitstream Cyberbit, which was about the coolest thing a font geek could get their hands on in 1998.
The most basic version of Unicode defines characters 0–65535, with the first 0–255 characters defined as identical to Latin-1 (for some modicum of compatibility with older systems).
One of the great things about the Unicode spec is the UTF-8 encoding. The idea behind UTF-8 is that the majority of characters will be in that standard ASCII set. So if the eighth bit of a character is a zero, then the other seven bits are just plain ASCII. If the eighth bit is 1, then it’s some sort of extended format. At which point the remaining bits determine how many additional characters (usually two) are required to encode the value for that character. It’s a very clever scheme because it degrades nicely, and provides a great deal of backward compatibility with the large number of systems still requiring only ASCII.
Of course, assuming that ASCII characters will be most predominant is to some repeating the same bias as back in the 1960s. But I think this is an academic complaint, and the benefits of the encoding far outweigh the negatives.
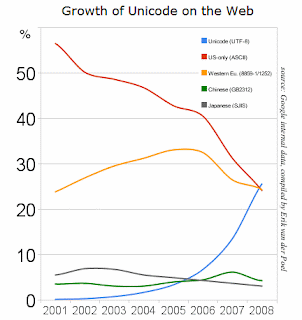 Anyhow, the purpose of this post was to write that Google reported yesterday that Unicode adoption on the web has passed ASCII and Western European. This doesn’t mean that English language characters have been passed up, but rather that the number of pages encoded using Unicode (usually in UTF-8 format), has finally left behind the archaic ASCII and Western European formats. The upshot is that it’s a sign of us leaving the dark ages—almost 20 years since the internet was made publicly available, and since the start of the Unicode consortium, we’re finally starting to take this stuff seriously.
Anyhow, the purpose of this post was to write that Google reported yesterday that Unicode adoption on the web has passed ASCII and Western European. This doesn’t mean that English language characters have been passed up, but rather that the number of pages encoded using Unicode (usually in UTF-8 format), has finally left behind the archaic ASCII and Western European formats. The upshot is that it’s a sign of us leaving the dark ages—almost 20 years since the internet was made publicly available, and since the start of the Unicode consortium, we’re finally starting to take this stuff seriously.
The Processing book also has a bit of background on ASCII and Unicode in an Appendix, which includes more about character sets and how to work with them. And future editions of vida will also cover such matters in the Parse chapter.

 A great
A great 
